
采用双注意力机制Deeplabv3+算法的遥感影像语义分割
|
刘文祥(1994—),男,江西高安人,硕士,主要研究方向为机器视觉和人工智能算法应用,(E-mail) 1609192581@qq.com。 |
收稿日期: 2019-10-11
要求修回日期: 2020-02-17
网络出版日期: 2020-05-15
版权
Remote Sensing Image Segmentation Using Dual Attention Mechanism Deeplabv3+ Algorithm
Received date: 2019-10-11
Request revised date: 2020-02-17
Online published: 2020-05-15
Copyright
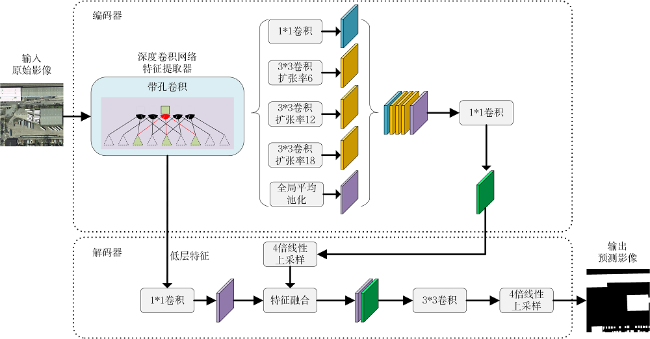
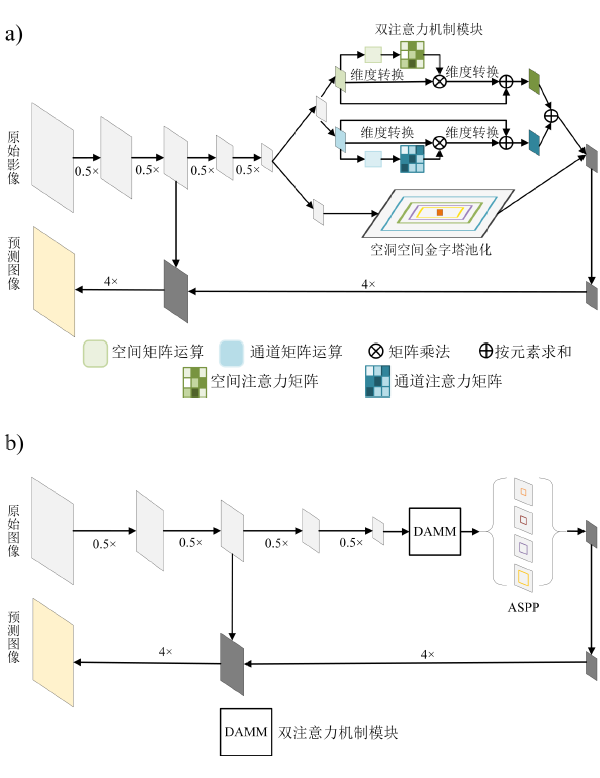
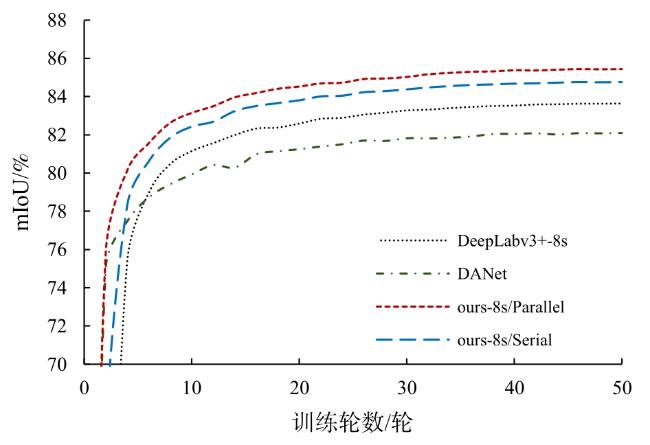
针对DeepLabv3+网络在遥感影像上呈现出拟合速度慢,边缘目标分割不精确,大尺度目标分割类内不一致、存在孔洞等缺陷,提出在该网络中引入双注意力机制模块(Dual Attention Mechanism Module, DAMM),设计并实现了将DAMM结构与ASPP(Atous Spatial Pyramid Pooling)层串联或并联的2种不同连接方式网络模型 ,串联连接方式中先将特征图送入DAMM后,再经过ASPP结构;并联连接方式中将双注意力机制层与ASPP层并行连接,网络并行处理主干网提取特征图,再融合两层处理特征信息。将改进的2种方法通过INRIA Aerial Image高分辨率遥感影像数据集验 证,结果表明,串联或并联方式2种网络都能有效改善Deeplabv3+的不足,并联方式网络性能更好,其对原网络缺陷改善效果更明显,并在测试数据集上mIoU达到85.44%,比Deeplabv3+提高了1.8%,而串联方式网络提高了1.12%。并联结构网络更符合本文需求,其形成了一种对DeepLabv3+网络上述问题进行统一改善的方案。
关键词: 遥感影像; 深度学习; DeepLabv3+; 注意力机制; 语义分割
刘文祥 , 舒远仲 , 唐小敏 , 刘金梅 . 采用双注意力机制Deeplabv3+算法的遥感影像语义分割[J]. 热带地理, 2020 , 40(2) : 303 -313 . DOI: 10.13284/j.cnki.rddl.003229
Remote sensing image processing technology based on deep learning can prospectively be used to determine the characteristics of large numbers of remote sensing image data and complex scenes. However, deep-learning algorithms in remote sensing image processing have certain shortcomings, e.g., the popular DeepLabv3+ network has slow fitting speeds, inaccurate edge target segmentation, inconsistencies, and holes in large-scale target segmentation. We therefore proposed a method for introducing a Dual Attention Mechanism Module (DAMM) to DeepLabv3+ to address the above deficiencies. We designed two different network models that connected the DAMM structure to the Atous Spatial Pyramid Pooling (ASPP) layer in series or parallel. In the serial connection method, the feature map was first sent to the DAMM and then passed through the ASPP structure. Furthermore, the feature map was defused with middle-low layer feature information through the decoder layer and restored to the original image resolution. In the parallel connection method, the DAMM and ASPP layers processed the feature map extracted from the backbone network in parallel and subsequently fused the processed feature map information. The mixed feature map was restored to its original resolution by the decoder. The two improved methods were verified by the INRIA Aerial Image high-resolution remote sensing dataset. The results showed that both the series and parallel methods could effectively improve the shortcomings of Deeplabv3+. The experimental results showed that the parallel network had superior performance, and improvements in the original network defects were more obvious. The parallel method achieved a higher score [85.44% Mean Intersection Over Union (MIOU)] in the test dataset, which was 1.8% higher than Deeplabv3+. And the serial network increased by 1.12% compared to Deeplabv3+. The effects of the position and channel attention mechanisms in the DAMM structure were also determined. The ablation study results showed that the channel and position attention mechanisms improved the performance of the Deeplabv3+ model. In the test set, the channel and position attention mechanism mIoU increased by 0.95 and 1.32%, respectively. The experiments revealed that the position attention mechanism had a greater effect on edge target segmentation, the channel attention mechanism had a greater effect on large-scale hole phenomena, and the channel and position attention mechanism promoted network fitting speed in training. The proposed improved DeepLabv3+ algorithm can provide a scientific basis and reference for semantic segmentation of big data remote sensing images.

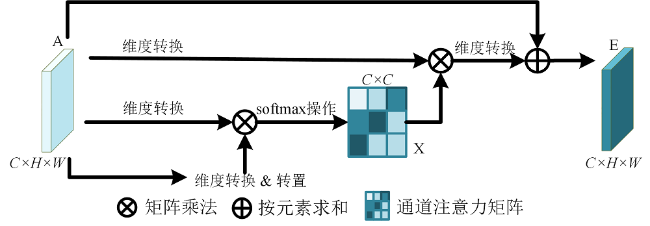
图2 位置注意力模块(Fu et al., 2019)Fig.2 Position attention module |
图3 通道注意力模块(Fu et al., 2019)Fig.3 Channel attention module |
表1 双注意力机制模块与ASPP结构不同连接方式网络实验结果对比Table 1 Comparison of network experimental results of different connection modes of the Dual Attention Mechanism Module and ASPP structure |
| 网络模型 | 步数 | mIoU/% |
|---|---|---|
| Deeplabv3+ | 16 | 82.13 |
| Deeplabv3+ | 8 | 83.64 |
| 串联结构网络 | 16 | 83.51 |
| 串联结构网络 | 8 | 84.76 |
| 并联结构网络 | 16 | 84.12 |
| 并联结构网络 | 8 | 85.44 |
表2 改进的DeepLabv3+网络与其他网络在INRIA Aerial Imaget的测试集结果对比Table 2 Comparison of the test set results of the improved DeepLabv3+ network in INRIA Aerial Image compared with other networks |
| 网络模型 | mIoU/% | 房屋(IoU)/% | 精度/% | 时间/(FPS) |
|---|---|---|---|---|
| FCN-8s | 78.21 | 66.95 | 92.31 | 7.69 |
| SegNet | 79.54 | 67.65 | 92.74 | 9.72 |
| DeepLabv3 | 81.96 | 72.10 | 93.26 | 5.98 |
| DANet | 82.10 | 72.59 | 93.14 | 5.71 |
| 陈天华 等(2018) | — | 69.42 | 95.22 | — |
| DeepLabv3+ | 83.64 | 74.65 | 93.94 | 5.66 |
| 串联结构网络 | 84.76 | 75.57 | 94.24 | 5.38 |
| 并联结构网络 | 85.44 | 76.13 | 94.86 | 5.32 |
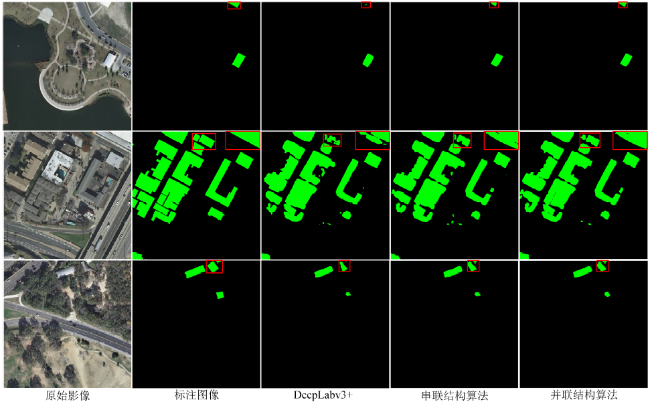
图5 提出的两种网络与DeepLabv3+模型在边缘目标分割中效果注:红色方框中为不同网络的边缘目标分割效果及Groundtruth。 Fig.5 The effect maps of the two proposed networks and DeepLabv3+ model in edge target segmentation. |
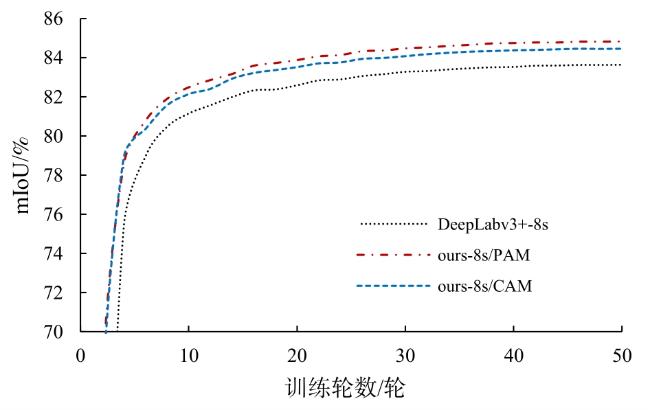
表3 注意力机制消融实验结果对比Table 3 Comparison of experimental results of attention mechanism ablation |
| 网络模型 | 位置注意力模块 | 通道注意力模块 | mIoU/% |
|---|---|---|---|
| Deeplabv3+ | 83.51 | ||
| 并联结构网络 | √ | 84.83 | |
| 并联结构网络 | √ | 84.46 | |
| 并联结构网络 | √ | √ | 85.44 |
| [1] |
|
| [2] |
|
| [3] |
陈天华, 郑司群, 于峻川 . 2018. 采用改进DeepLab网络的遥感图像分割. 测控技术, 37(11):40-45.
[
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
王中宇, 倪显扬, 尚振东 . 2019. 利用卷积神经网络的自动驾驶场景语义分割. 光学精密工程, 27(11):2429-2438.
[
|
| [17] |
|
| [18] |
袁立, 袁吉收, 张德政 . 2019. 基于DeepLab-V3+的遥感影像分类. 激光与光电子学进展, 56(15):236-243.
[
|
| [19] |
|
/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}