
融合CTGAN与机器学习的温州市台风灾害损失评估方法研究
参与模型训练,参与论文修改
|
孙沣楠(2000—),男,河南周口人,硕士研究生,研究方向为灾害风险分析与评估,E-mail:fengnansun@mail.dlut.edu.cn |
收稿日期: 2025-06-07
修回日期: 2025-07-26
网络出版日期: 2026-03-07
基金资助
温州市未来城市研究院开放基金项目(WL2023009);浙江省自然资源厅2024年度科技项目(2024ZJDZ036);浙江省教育厅科研项目(Y202456064)
版权
Typhoon Disaster Loss Assessment Method for Wenzhou City by Integrating CTGAN and Machine Learning
Received date: 2025-06-07
Revised date: 2025-07-26
Online published: 2026-03-07
Copyright
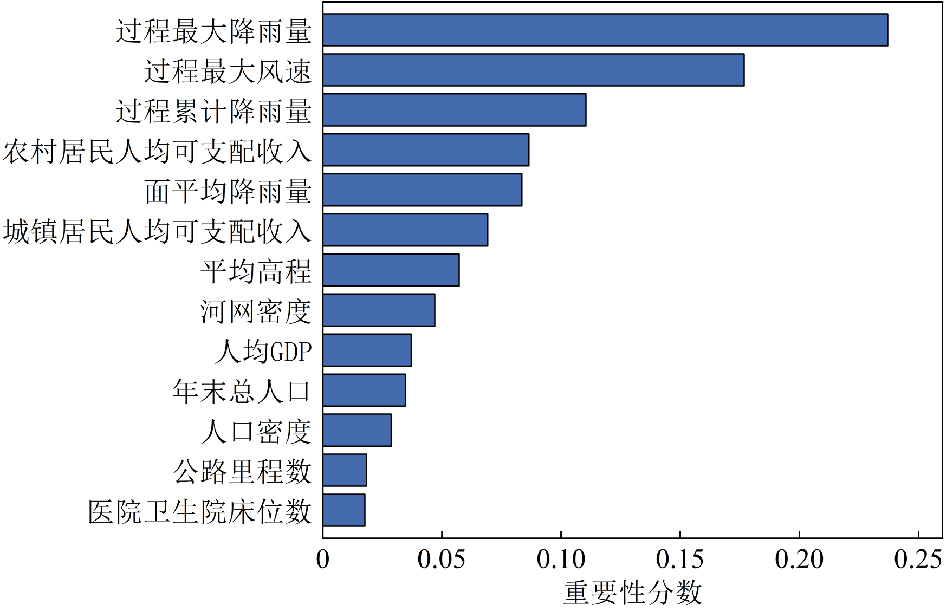
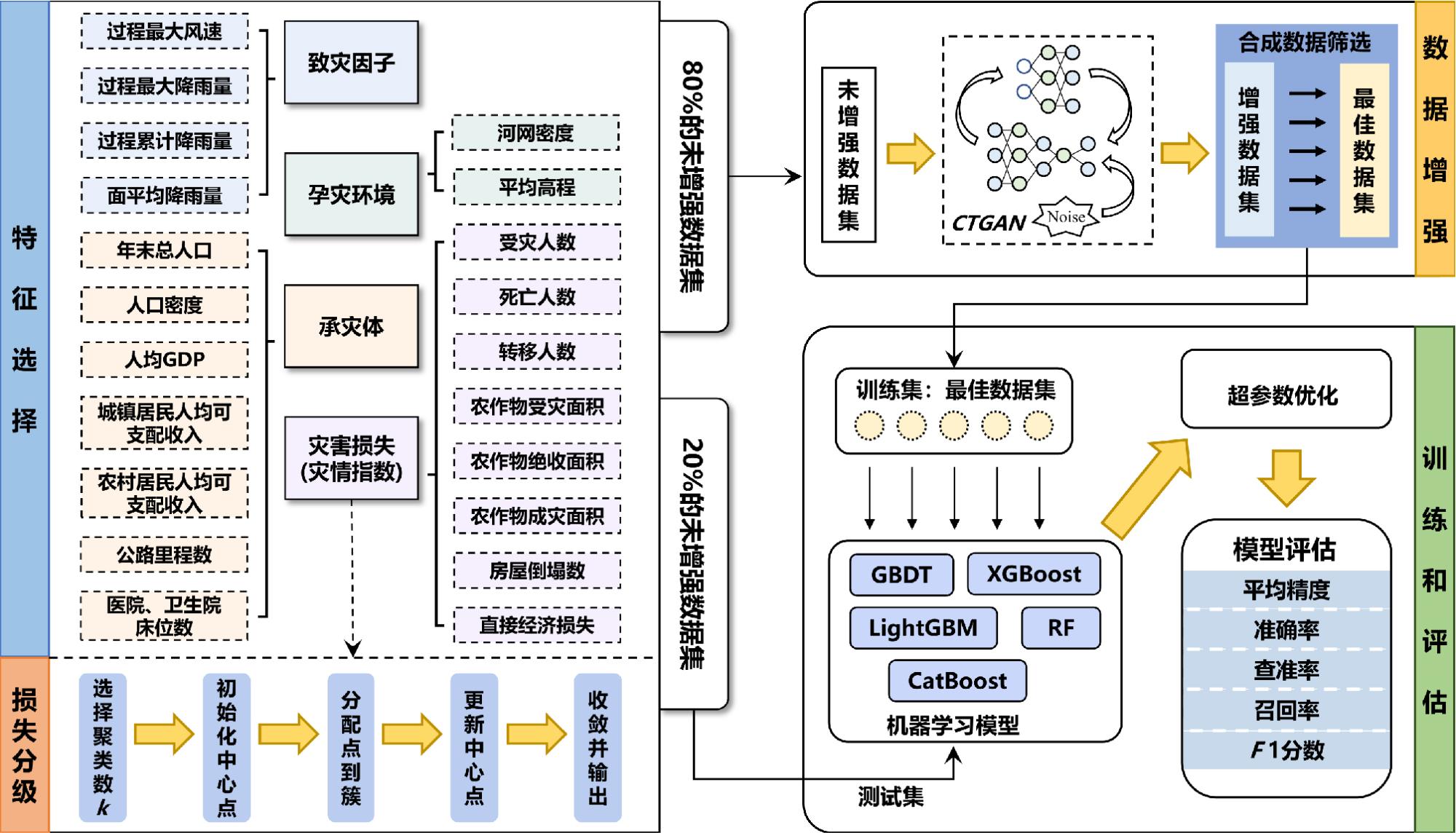
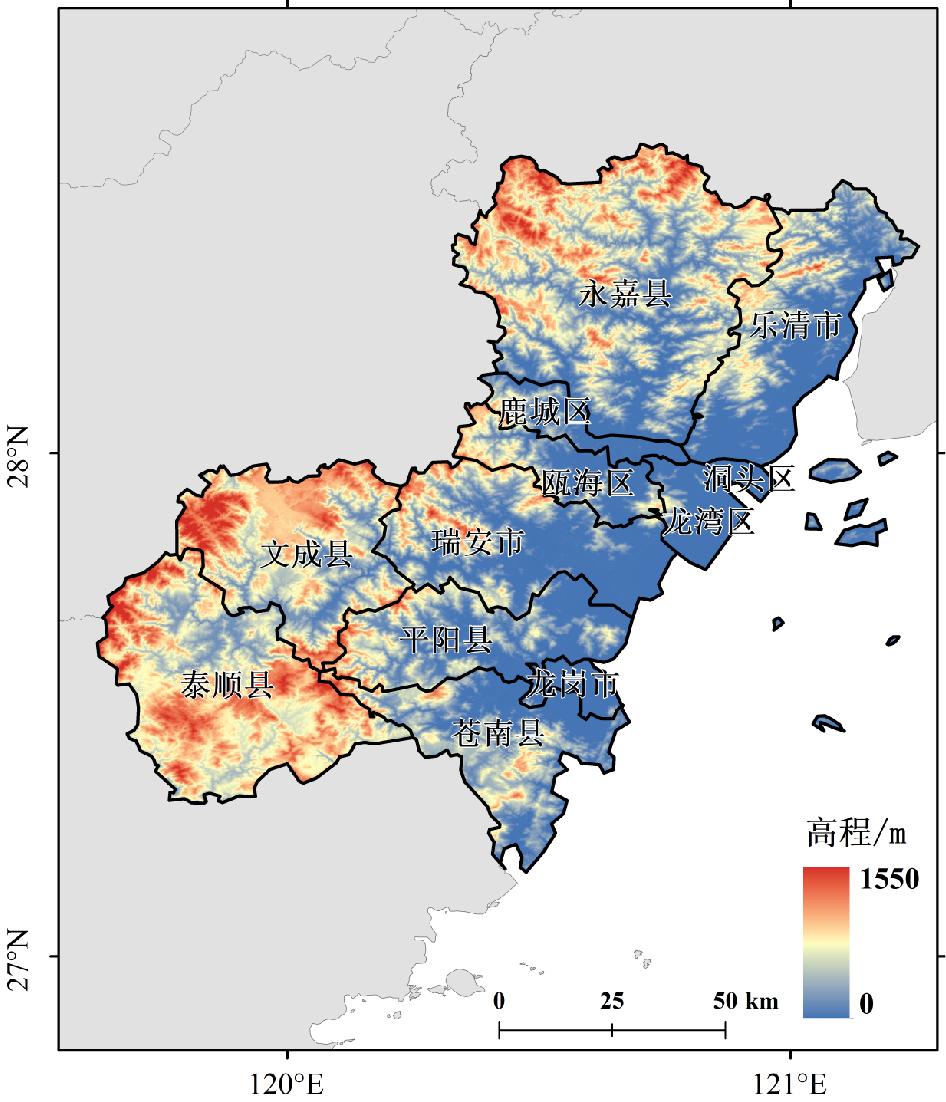
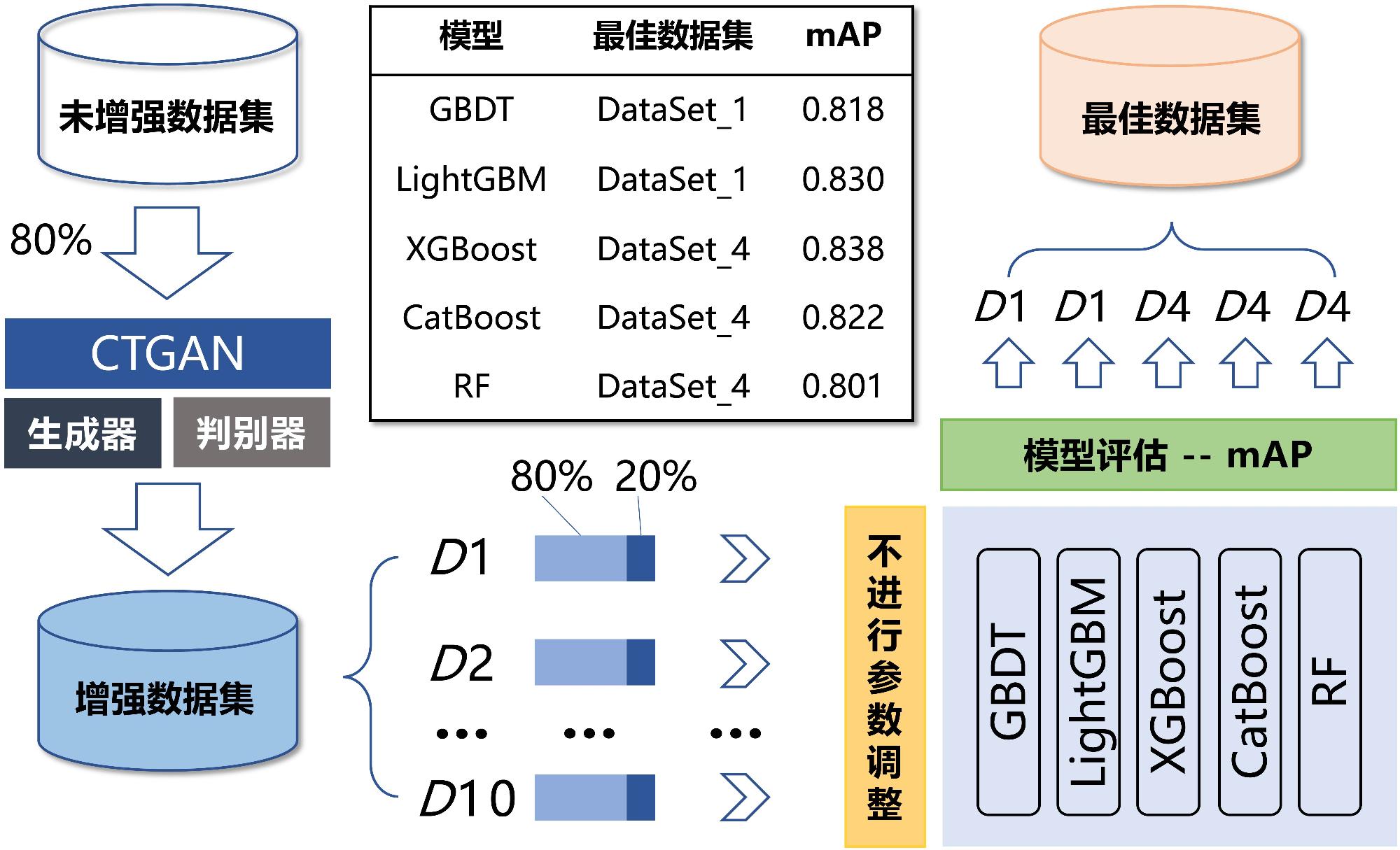
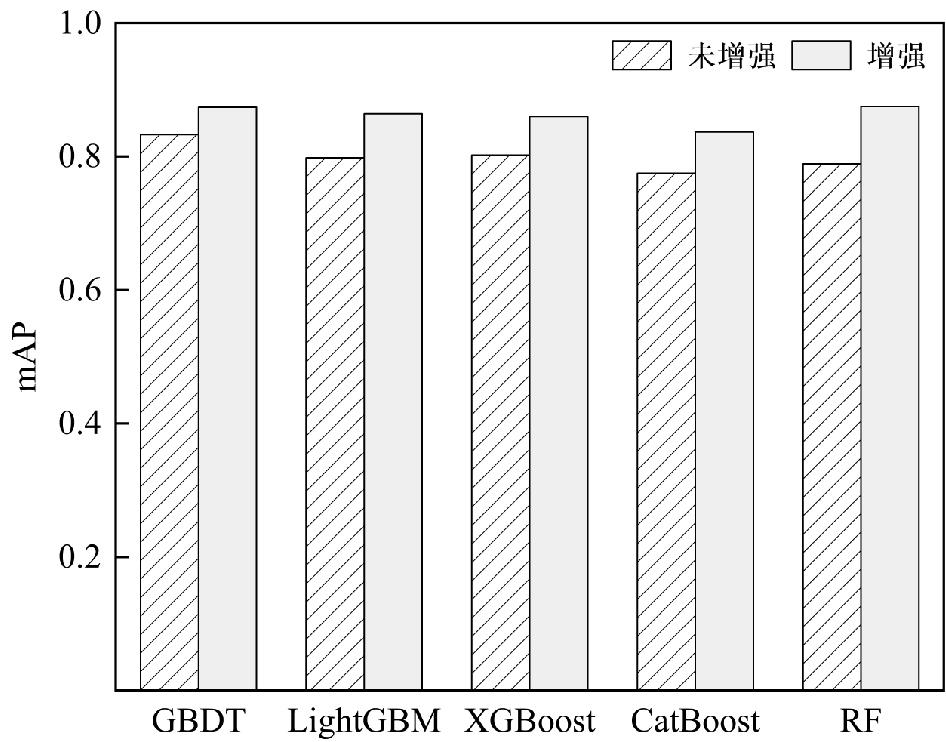
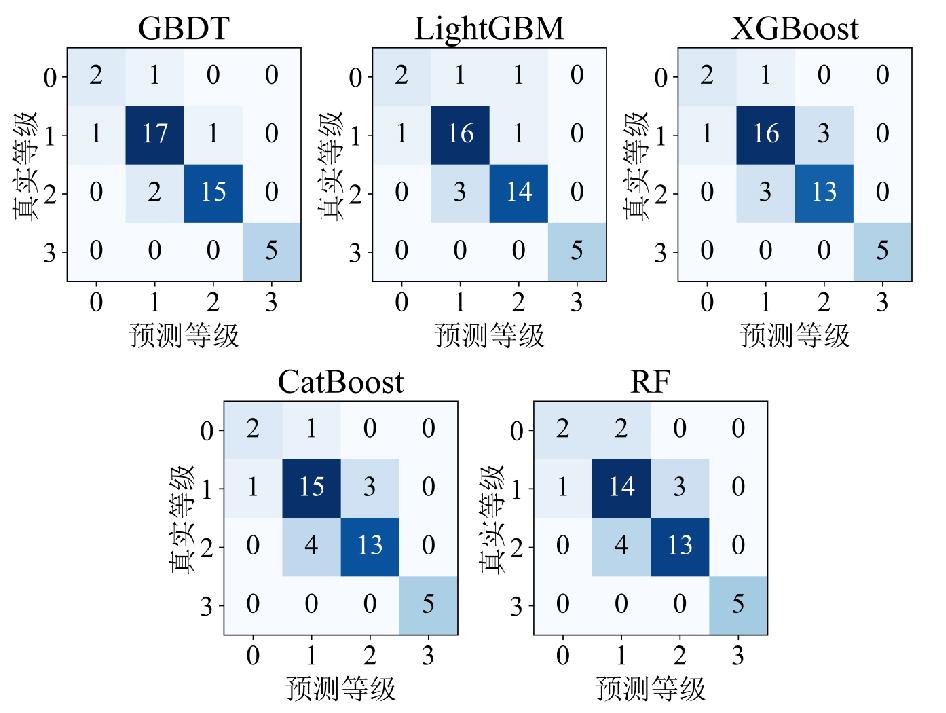
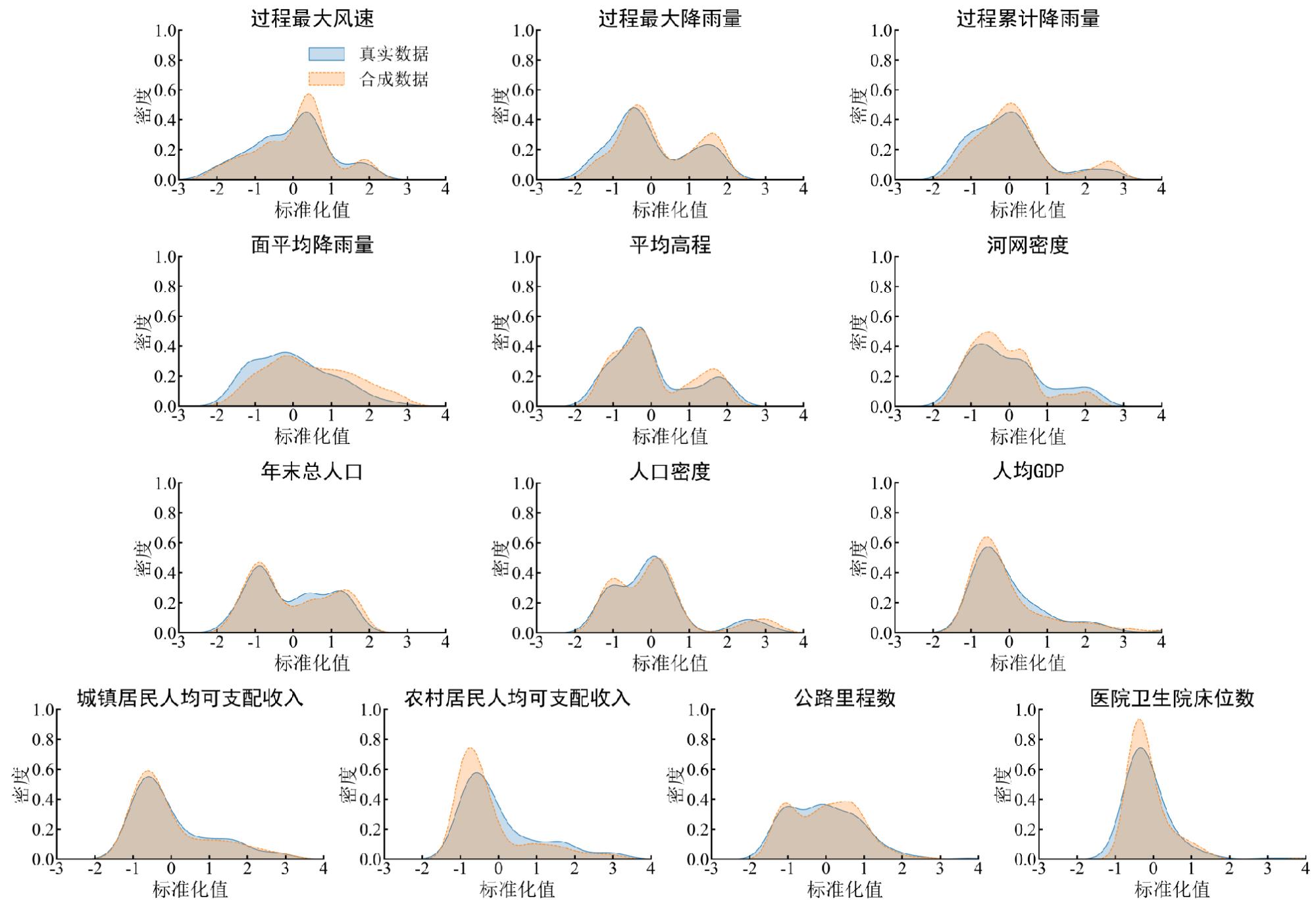
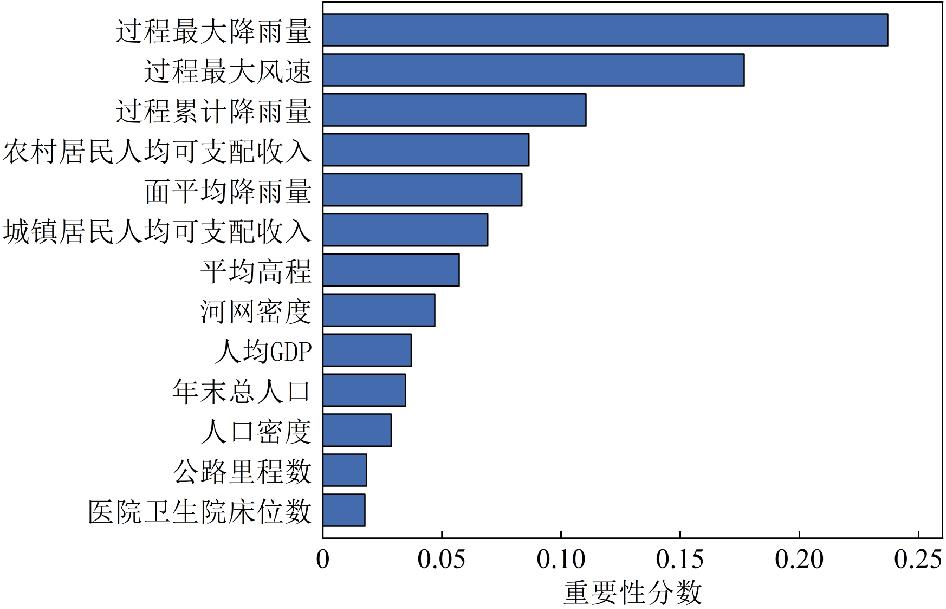
为缓解台风灾害损失评估中数据样本缺失与类别不平衡问题,文章提出了一种融合CTGAN数据增强与机器学习算法的评估方法。以浙江省温州市为研究区,基于1994—2020年的20个台风案例,整合致灾因子、孕灾环境与承灾体等数据,构建了包含13项指标的数据集,基于灾情损失指数采用K-means聚类方法划分4个灾害损失等级。在此基础上,利用CTGAN模型生成增强数据集,并分别基于GBDT、XGBoost、LightGBM、CatBoost和随机森林构建灾害损失评估模型。结果表明,CTGAN能够有效学习原始小样本数据的特征分布规律,所生成样本在整体统计特征上与真实数据保持较高一致性,从而在一定程度上缓解了样本稀缺对模型训练的影响。然而,模型性能并未随合成样本数量的增加而持续提升,适度的样本规模更有利于模型稳定性;在多模型对比中,GBDT模型在分类性能与泛化能力方面表现最优,尤其在中等灾害损失等级的判别中具有更强的区分能力,表明该评估框架在小样本条件下开展台风灾害损失评估的有效性与应用潜力。
孙沣楠 , 丛海勇 , 章豪 , 王云阁 , 徐刚 . 融合CTGAN与机器学习的温州市台风灾害损失评估方法研究[J]. 热带地理, 2026 , 46(3) : 483 -494 . DOI: 10.13284/j.cnki.rddl.20250382
Accurate assessment of typhoon-induced disaster losses is often hindered by limited historical data and severe class imbalances, especially in regions with infrequent but high-impact events. These challenges reduce the robustness and generalizability of predictive models, leading to unreliable assessments of potential disaster severity. To address these issues, this study proposes an integrated evaluation method that combines data augmentation using a CTGAN with multiple machine learning algorithms. The objective was to enhance sample diversity, alleviate class imbalance, and improve the accuracy and stability of disaster loss predictions. Wenzhou City, located in Zhejiang Province, China, was selected as the study area because of its frequent exposure to typhoon-related hazards. Twenty typhoon cases from 1994 to 2020 were collected, and a structured dataset was constructed using 13 key indicators. These indicators cover three dimensions: (1) hazard-inducing factors such as maximum wind speed and accumulated rainfall; (2) environmental background conditions, including elevation, river network density, and landform; and (3) socioeconomic exposure and vulnerability, reflected by variables such as population density, GDP per capita, and infrastructure indicators, such as road length and hospital bed count. To represent the level of disaster impact for each event quantitatively, a disaster loss index was calculated and used as the input for k-means clustering. This unsupervised learning approach classified 20 typhoon events into four distinct loss severity levels, forming the basis for subsequent supervised classification tasks. To overcome the limitations of class imbalance, the CTGAN model was employed to generate synthetic samples under specific class-conditional constraints. The generated samples were incorporated into the training set to enrich underrepresented classes and improve the representativeness of the dataset. Five widely used machine-learning models were trained and evaluated: GBDT, XGBoost, LightGBM, CatBoost, and Random Forest. The experimental results demonstrated that the GBDT model outperformed the others in terms of both classification accuracy and generalization performance. This model showed the most consistent results across multiple metrics, including mAP, precision, recall, F1-score, and accuracy. Additionally, a comparative analysis was conducted to explore the influence of synthetic data volume on model performance. The findings revealed that simply increasing the number of synthetic samples does not guarantee continuous improvement; rather, an optimal range of sample sizes exists beyond which model stability may plateau or even decline. This study provides a practical and scalable methodological framework for typhoon disaster loss assessments in data-constrained environments. By leveraging generative modeling and ensemble learning techniques, this study offers insights into the effective application of data-driven methods to support disaster preparedness, emergency response planning, and resilience analysis in other hazard-prone regions.
Key words: typhoon; disaster assessment; machine learning; data augmentation; Wenzhou City
表1 数据说明Table 1 Data description |
| 数据类型 | 数据名称 | 数据内容 | 数据来源 |
| 致灾因子 | 1994—2020年温州市各台风事件 区县测站气象数据 | 过程最大风速、过程最大降雨量、 过程累计降雨量等 | 温州市气象局 |
| 孕灾环境 | 温州市各区县河网分布、地形数据 | 平均高程、河网密度等 | 中国科学院地理科学与资源研究所 |
| 承灾体 | 1994—2020年温州市社会经济与 基础设施数据 | 人口密度、人均GDP、公路里程数、 医院卫生院床位数等 | 温州市统计年鉴 |
| 灾害损失 | 1994—2020年温州市各台风事件 区县灾情统计数据 | 受灾人数、转移人数、农作物受灾面积、 房屋倒塌数、直接经济损失等 | 温州市应急管理局 |
表2 灾情指标权重Table 2 Weighting of disaster indicators |
| 一级指标 | 二级指标 | |||
| 指标名 | 权重 | 指标名 | 权重 | |
| 人口损失 | 0.5 | 受灾人数 | 0.1 | |
| 死亡人数 | 0.25 | |||
| 转移人数 | 0.15 | |||
| 农业损失 | 0.2 | 农作物受灾面积 | 0.1 | |
| 农作物绝收面积 | 0.05 | |||
| 农作物成灾面积 | 0.05 | |||
| 房屋损失 | 0.15 | 房屋倒塌数 | 0.15 | |
| 经济损失 | 0.15 | 直接经济损失 | 0.15 | |
表3 基于K-means聚类算法的灾害损失等级划分Table 3 Disaster loss classification based on K-means clustering algorithm |
| 灾害损失等级 | 类别比例/% | 灾情指数范围 |
| Ⅰ级 | 7.2 | DI<-0.79 |
| Ⅱ级 | 46.8 | -0.79≤DI <-0.30 |
| Ⅲ级 | 35.5 | -0.30≤DI<0.81 |
| Ⅳ级 | 10.5 | 0.81≤DI<3.0 |
表4 模型最优参数组合Table 4 Optimal parameter combinations for the model |
| 超参数名称 | GBDT | LightGBM | XGBoost | CatBoost | RF |
| n_estimators | 100 | 50 | 100 | 100 | |
| max_depth | 4 | 5 | 4 | 6* | 10 |
| learning_rate | 0.1 | 0.1 | 0.05 | 0.1 | — |
| max_features | 0.6 | — | — | — | 0.7 |
| min_samples_split | 15 | — | — | — | 5 |
| min_samples_leaf | 10 | 20* | — | 1* | 2 |
| subsample | — | 0.7* | 0.7 | — | — |
| colsample_bytree | — | 0.9* | 0.8 | — | — |
| num_leaves | — | 15 | — | — | — |
| border_count | — | — | — | 32 | — |
注:用*标出的为近似项。如LightGBM中的bagging_fraction、feature_fraction和min_data_in_leaf分别近似于subsample、colsample_bytree和min_samples_leaf;CatBoost中的depth和min_data_in_leaf近似于max_depth和min_samples_leaf。 |
表5 五种机器学习模型的性能评估Table 5 Performance evaluation of five machine learning models |
| 模型 | Accuracy | Recall | Precision | F1 | mAP |
| GBDT | 0.886 | 0.864 | 0.861 | 0.862 | 0.874 |
| LightGBM | 0.841 | 0.835 | 0.803 | 0.816 | 0.864 |
| XGBoost | 0.818 | 0.820 | 0.820 | 0.820 | 0.860 |
| CatBoost | 0.795 | 0.807 | 0.805 | 0.806 | 0.837 |
| RF | 0.795 | 0.807 | 0.761 | 0.774 | 0.875 |
表6 不同规模合成数据集对性能的影响Table 6 Impact of different sizes of synthetic datasets on performance |
| 样本量/个 | mAP |
| 500 | 0.874 |
| 0.864 | |
| 0.887 | |
| 2 000 | 0.824 |
|
陈楷俊, 陈艺仪, 陈菁. 近30年粤东地区台风灾害风险评估与分析. 水土保持研究, 2019, 26 (3): 362- 366,372.
Chen Kaijun, Chen Yiyi, and Chen Jing. Risk Assessment and Analysis of Typhoon Disaster in East Guangdong in the Period 1989-2017. Research of Soil and Water Conservation, 2019, 26 (3): 362- 366,372.
|
|
陈文方, 徐伟, 史培军. 长三角地区台风灾害风险评估. 自然灾害学报, 2011, 20 (4): 77- 83.
Chen Wenfang, Xu Wei, and Shi Peijun. Risk Assessment of Typhoon Disaster at County Level in the Yangtze River Delta of China. Journal of Natural Disasters, 2011, 20 (4): 77- 83.
|
|
陈香, 陈静, 王静爱. 福建台风灾害链分析——以2005年“龙王”台风为例. 北京师范大学学报(自然科学版), 2007 (2): 203- 208.
Chen Xiang, Chen Jing, and Wang Jing’ai. Analysis on Typhoon Disaster Chain in Fujian: A Case Study of Typhoon Longwang in 2005. Journal of Beijing Normal University(Natural Science), 2007 (2): 203- 208.
|
|
Chou Jieming, Dong Wenjie, Tu Gang, and Xu Yuan. 2020. Spatiotemporal Distribution of Landing Tropical Cyclones and Disaster Impact Analysis in Coastal China During 1990-2016. Physics and Chemistry of the Earth, Parts A/B/C, 115: 102830.
|
|
Du Xuexue, Li Xiaomin, Zhang Suming, Zhao Tangqi, Hou Qi, Jin Xifang, and Zhang Jie. High-Accuracy Estimation Method of Typhoon Storm Surge Disaster Loss under Small Sample Conditions by Information Diffusion Model Coupled with Machine Learning Models. International Journal of Disaster Risk Reduction, 2022, 82, 103307.
|
|
樊琦, 梁必骐. 热带气旋灾情的预测及评估. 地理学报, 2000, 55 (S1): 52- 56.
Fan Qi and Liang Biqi. The Evaluation of Disastrous Losses Caused by Tropical Cyclones. Acta Geographica Sinica, 2000, 55 (S1): 52- 56.
|
|
方伟华, 林伟. 面向灾害风险评估的台风风场模型研究综述. 地理科学进展, 2013, 32 (6): 852- 867.
Fang Weihua and Lin Wei. A Review on Typhoon Wind Field Modeling for Disaster Risk Assessment. Progress in Geography, 2013, 32 (6): 852- 867.
|
|
Feng Junjie, Zhang Yu, Xu Jianjun, Hu Jiazheng, Tang Yuan, and Liang Xiwen. Dynamic Assessment and Prediction of Typhoon Disaster Risk in Beibu Gulf: From the Analytic Hierarchy Process and Projection Pursuit Clustering Perspective. Science of The Total Environment, 2025, 977, 179389.
|
|
Feng Lihua and Luo Gaoyuan. Analysis on Fuzzy Risk of Landfall Typhoon in Zhejiang Province of China. Mathematics and Computers in Simulation, 2009, 79 (11): 3258- 3266.
|
|
Goodfellow I, Pouget A J, Mirza M, Xu Bing, Warde F D, Ozair S, Courville A, and Bengio Y. Generative Adversarial Networks. Communications of the ACM, 2020, 63 (11): 139- 144.
|
|
何玥双, 江辉仙. 台风灾害链时序性风险评估研究. 灾害学, 2024, 39 (4): 213- 218.
He Yueshuang and Jiang Huixian. Study on the Temporal Risk Assessment of Typhoon Disaster Chain. Journal of Catastrophology, 2024, 39 (4): 213- 218.
|
|
贺山峰, 李铮, 陈超冰, 吴绍洪, 潘涛. 海南省登陆台风特征演变及其危险性分析. 地理科学进展, 2023, 42 (7): 1355- 1364.
He Shanfeng, Li Zheng, Chen Chaobing, Wu Shaohong, and Pan Tao. Evolution of Landing Typhoon Characteristics and Typhoon Hazards in Hainan Province, China. Progress in Geography, 2023, 42 (7): 1355- 1364.
|
|
李广桃, 姚才, 刘合香. 基于三维联合分布的登陆影响广西县域超强台风“威马逊”的灾害风险评估. 海洋预报, 2023, 40 (3): 85- 96.
Li Guangtao, Yao Cai, and Liu Hexiang. Disaster Risk Assessment of Super Typhoon Rammasun Making Landfall in Guangxi Based on Three-Dimensional Joint Distribution Function. Marine Forecasts, 2023, 40 (3): 85- 96.
|
|
梁必骐, 梁经萍, 温之平. 中国台风灾害及其影响的研究. 自然灾害学报, 1995 (1): 84- 91.
Liang Biqi, Liang Jingping, and Wen Zhiping. Study of Typhoon Disasters and Their Impacts in China. Journal of Natural Disasters, 1995 (1): 84- 91.
|
|
林沛延, 林陪晖, 王俊, 王乃玉. 基于机器学习方法的浙江省台风灾害风险评估和动态风险预报. 自然灾害学报, 2023, 32 (4): 13- 24.
Lin Peiyan, Lin Yuhui, Wang Jun, and Wang Naiyu. Typhoon Disaster Risk Assessment and Dynamic Risk Prediction in Zhejiang Province Based on Machine Learning Approach. Journal of Natural Disasters, 2023, 32 (4): 13- 24.
|
|
刘蓓蓓, 赵飞, 王曦, 闫雪, 林森. 多源数据驱动的台风动态风险评估. 热带地理, 2024, 44 (6): 1102- 1112.
Liu Beibei, Zhao Fei, Wang Xi, Yan Xue, and Lin Sen. Multi-Source Data-Driven Modeling of Typhoon Dynamic Risk Assessment. Tropical Geography, 2024, 44 (6): 1102- 1112.
|
|
刘洪良, 罗年学, 赵前胜. 基于灾害复杂网络的深圳台风灾害链风险分析. 灾害学, 2023, 38 (4): 228- 234.
Liu Hongliang, Luo Nianxue, and Zhao Qiansheng. Risk Analysis of Typhoon Disaster Chain in Shenzhen Based on Complex Network. Journal of Catastrophology, 2023, 38 (4): 228- 234.
|
|
刘淑贤, 张立生, 刘扬, 王维国, 杨琨, 张源达. 基于机器学习的热带气旋灾害等级评估模型构建及其活动特征分析. 气象, 2024, 50 (3): 331- 343.
Liu Shuxian, Zhang Lisheng, Liu Yang, Wang Weiguo, Yang Kun, and Zhang Yuanda. Construction of Tropical Cyclone Disaster Grade Assessment Model Based on Machine Learning and Analysis Its Activity Characteristics. Meteorological Monthly, 2024, 50 (3): 331- 343.
|
|
Li Dan, Hu Tianliang, Dong Lili, and Ma Songhua. A Generalized Generation and Evaluation Method for Cutting Process Parameter Knowledge Based on CTGAN. Robotics and Computer-Integrated Manufacturing, 2025, 94, 102963.
|
|
Lin Peihui and Wang Naiyu. A Data-Driven Approach for Regional-Scale Fine-Resolution Disaster Impact Prediction under Tropical Cyclones. Natural Hazards, 2024, 120 (8): 7461- 7479.
|
|
Liu C F, Huang Lipai, Yin Kai, Brody S, and Mostafavi A. Flood Damage Cast: Building Flood Damage Nowcasting with Machine-Learning and Data Augmentation. International Journal of Disaster Risk Reduction, 2024, 114, 104971.
|
|
娄伟平, 陈海燕, 郑峰, 吴睿. 基于主成分神经网络的台风灾害经济损失评估. 地理研究, 2009, 28 (5): 1243- 1254.
Lou Weiping, Chen Haiyan, Zheng Feng, and Wu Rui. Economic Loss Assessment of Typhoon Based on Principal Component Analysis and Neural Networks. Geographical Research, 2009, 28 (5): 1243- 1254.
|
|
卢文芳. 上海地区热带气旋灾情的评估和灾年预测. 自然灾害学报, 1995 (3): 40- 45.
Lu Wenfang. Assessment and Prediction of Disastrous Losses Due to Tropical Cyclone in Shanghai. Journal of Natural Disasters, 1995 (3): 40- 45.
|
|
卢耀健, 刘合香, 王萌. 基于组合权重和模糊随机方法的台风灾害风险评估. 模糊系统与数学, 2020, 34 (2): 151- 163.
Lu Yajian, Liu Hexiang, and Wang Meng. Typhoon Disaster Risk Assessment Based on Combined Weights and Fuzzy Stochastic Methods. Fuzzy Systems and Mathematics, 2020, 34 (2): 151- 163.
|
|
马清云, 李佳英, 王秀荣, 王维国, 高兰英. 基于模糊综合评价法的登陆台风灾害影响评估模型. 气象, 2008 (5): 20- 25.
Ma Qingyun, Li Jiaying, Wang Xiurong, Wang Weiguo, and Gao Lanying. A Fuzzy Synthetic Evaluation Model for Typhoon Disaster. Meteorological Monthly, 2008 (5): 20- 25.
|
|
Meng Chenna, Xu Wei, Su Peng, Qin Lianjie, Liao Xinli, and Zhang Junlin. Quantitative Assessment of Population Risk to Tropical Cyclones using Hybrid Modeling Combining GAM and XGBoost: A Case Study of Hainan Province. International Journal of Disaster Risk Reduction, 2024, 110, 104650.
|
|
欧进萍, 段忠东, 常亮. 中国东南沿海重点城市台风危险性分析. 自然灾害学报, 2002 (4): 9- 17.
Ou Jinping, Duan Zhongdong, and Chang Liang. Typhoon Risk Analysis for Key Coastal Cities in Southeast China. Journal of Natural Disasters, 2002 (4): 9- 17.
|
|
Padilla R, Netto S L, and Da-Silva E A B. 2020. A Survey on Performance Metrics for Object-Detection Algorithms. In: IEEE. 2020 International Conference on Systems, Signals and Image Processing (IWSSIP). New York: IEEE, 237-242.
|
|
Patki N, Wedge R, and Veeramachaneni K. 2016. The Synthetic Data Vault. In: IEEE. Proceedings of the 2016 IEEE International Conference on Data Science and Advanced Analytics (DSAA). New York: IEEE, 399-410.
|
|
钱燕珍, 何彩芬, 杨元琴, 王继志. 热带气旋灾害指数的估算与应用方法. 气象, 2001 (1): 14- 18,24.
Qian Yanzhen, He Caifen, Yang Yuanqin, and Wang Jizhi. An Assessment of Damage Index for Tropical Cyclones. Meteorological Monthly, 2001 (1): 14- 18,24.
|
|
王洁, 杨奕杰, 王杰, 吕阳阳, 栾奎峰. 基于近20 a历史数据的中国沿海城市台风灾害风险评估. 海洋预报, 2021, 38 (5): 24- 30.
Wang Jie, Yang Yijie, Wang Jie, Lyu Yangyang, and Luan Kuifeng. Typhoon Disaster Risk Assessment of Coastal Cities in China Based on Historical Data over the Past 20 Years. Marine Forecasts, 2021, 38 (5): 24- 30.
|
|
王秀荣, 张立生, 李维邦. 台风灾害综合等级评判模型改进及应用分析. 气象, 2018, 44 (2): 304- 312.
Wang Xurong, Zhang Lisheng, and Li Weibang. Improvement and Application Analysis of the Comprehensive Grade Evaluation Model of Typhoon Disaster. Meteorological Monthly, 2018, 44 (2): 304- 312.
|
|
魏章进, 马华铃, 唐丹玲. 基于改进熵值法的台风灾害风险趋势评估. 灾害学, 2017, 32 (3): 7- 11.
Wei Zangjin, Ma Hualing, and Tang Danling. Trend Assessment of Typhoon Disasters Based on the Improved Entropy Method. Journal of Catastrophology, 2017, 32 (3): 7- 11.
|
|
徐良炎, 高歌. 近50年台风变化特征及灾害年景评估. 气象, 2005 (3): 41- 45.
Xu Laingyan and Gao Ge. Features of Typhoon in Recent 50 Years and Annual Disaster Assessment. Meteorological Monthly, 2005 (3): 41- 45.
|
|
许贵林, 黄兆泳. 基于AHP-熵组合赋权的广西台风灾害风险评价. 南宁师范大学学报(自然科学版), 2024, 41 (4): 86- 96.
Xu Guilin and Huang Zhaoyong. Risk Assessment of Typhoon Disasters in Guangxi Based on AHP-Entropy Combined Weighting. Journal of Nanning Normal University(Natural Science Edition), 2024, 41 (4): 86- 96.
|
|
杨绚, 张立生, 王铸. 基于机器学习算法的县域台风灾害经济损失风险评估. 热带气象学报, 2022, 38 (5): 651- 661.
Yang Xuan, Zhang Lisheng, and Wang Zhu. Risk Assessment for Typhoon Economic Losses in County-Based Units Using Machine Learning. Journal of Tropical Meteorology, 2022, 38 (5): 651- 661.
|
|
姚学祥, 田翠英. 台风灾害特点和成因的初步分析. 灾害学, 1989 (2): 62- 68.
Yao Xuexiang and Tian Cuiying. Preliminary Analysis of the Characteristics and Causes of Typhoon Disasters. Journal of Catastrophology, 1989 (2): 62- 68.
|
|
叶丁嘉, 王国复, 尹宜舟, 宋月旻, 孙劭. 基于灰色关联法的县域台风灾情评估方法初探. 海洋气象学报, 2019, 39 (1): 68- 75.
Ye Dingjia, Wang Guofu, Yin Yizhou, Song Yuemin, and Sun Shao. Study on Typhoon Disaster Assessment at County Level Based on Gray Relational Analysis. Journal of Marine Meteorology, 2019, 39 (1): 68- 75.
|
|
Yang Xiaoliu, Qin Xiaochen, Zhou Xiang, Chen Ying, and Gao Lu. Assessment of Disaster Mitigation Capability Oriented to Typhoon Disaster Chains: A Case Study of Fujian Province, China. Ecological Indicators, 2024, 167, 112621.
|
|
张月霞. 2014. 基于ADCIRC模式的台风风暴潮灾害风险评估方法研究与应用——以浙江台州为例. 青岛: 中国海洋大学.
Zhang Yuexia. 2014. Risk Assessment Method and Application of Typhoon Storm Surge Based on ADCIRC—A Case Study of Taizhou. Tsingtao: Ocean University of China.
|
|
Zhang Suming, Zhang Jie, Li Xiaomin, Du Xuexue, Zhao Tangqi, Hou Qi, and Jin Xifang. Estimating the Grade of Storm Surge Disaster Loss in Coastal Areas of China via Machine Learning Algorithms. Ecological Indicators, 2022, 136, 108533.
|
|
Zhang Yu, Wang Jiangjiang, Yin Zhiqiang, Shao Yuming, Kang Jian, and Ma Zherui. Mitigation Imbalance Distribution: Data Augmentation of Local Small Sample for Building Electricity Load in Time-Series Generative Adversarial Network. Journal of Building Engineering, 2025, 99, 111549.
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}